Data Model
This section discusses the components of the Aerospike data model and the relationships among them.
Components of the Aerospike schemaless data model
The Aerospike database does not require a traditional RDBMS schema. Rather, the data model is determined through your use of the system. For example, if you wanted to add a new data type to a record, you would write that data type into the record without having to first update any schema.
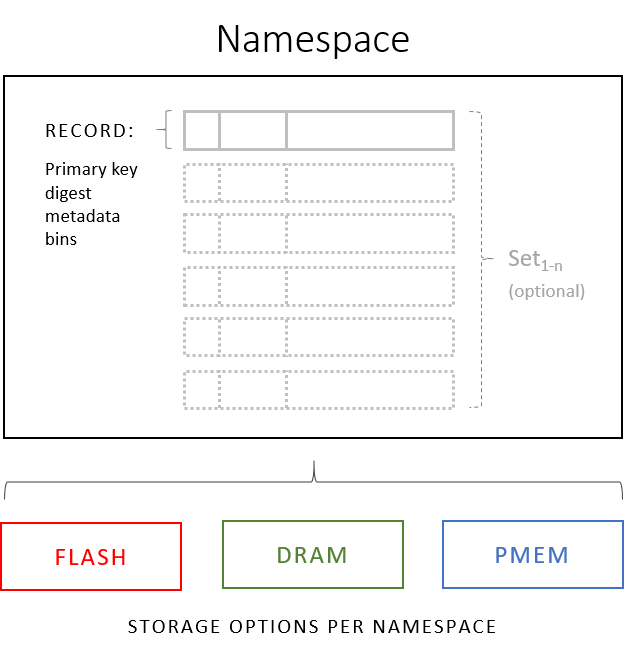
| Component | Description |
|---|---|
| physical storage | You can choose the specific type of storage you want for each namespace: NVMe Flash, DRAM, or Intel Optane Persistent Memory (PMem). Different namespaces in the same cluster can use distinct types of storage (see hybrid storage). The physical storage medium is also called the storage engine. |
| namespace | Similar to a tablespace in an RDBMS, a namespace is a collection of records that share one specific storage engine, with common policies such as replication factor, encryption and more. A database can contain multiple namespaces. |
| record | A record is an object similar to a row in an RDBMS. It is a contiguous storage unit for all the data uniquely identified by a single key. |
| set | Records can be optionally grouped into sets. Sets are similar to tables in an RDBMS, but without an explicit schema. |
| bin | A record is subdivided into bins, which are similar to columns in an RDBMS. Each bin has its own data type, and those do not need to agree between records. Secondary indexes can optionally be declared on bins. |
Physical storage
Varieties of physical storage are discussed in Hybrid Storage.
Namespaces
Namespaces are top-level data containers. The way you collect data in namespaces relates to how the data is stored and managed. A namespace contains records, indexes, and policies. Policies dictate namespace behavior, including:
- How data is physically stored.
- How many replicas exist for a record.
- When records expire.
For more information, see Configuring Namespaces.
A database can specify multiple namespaces, each with different policies to fit your application. You can consider namespaces physical containers that bind data to a storage device.
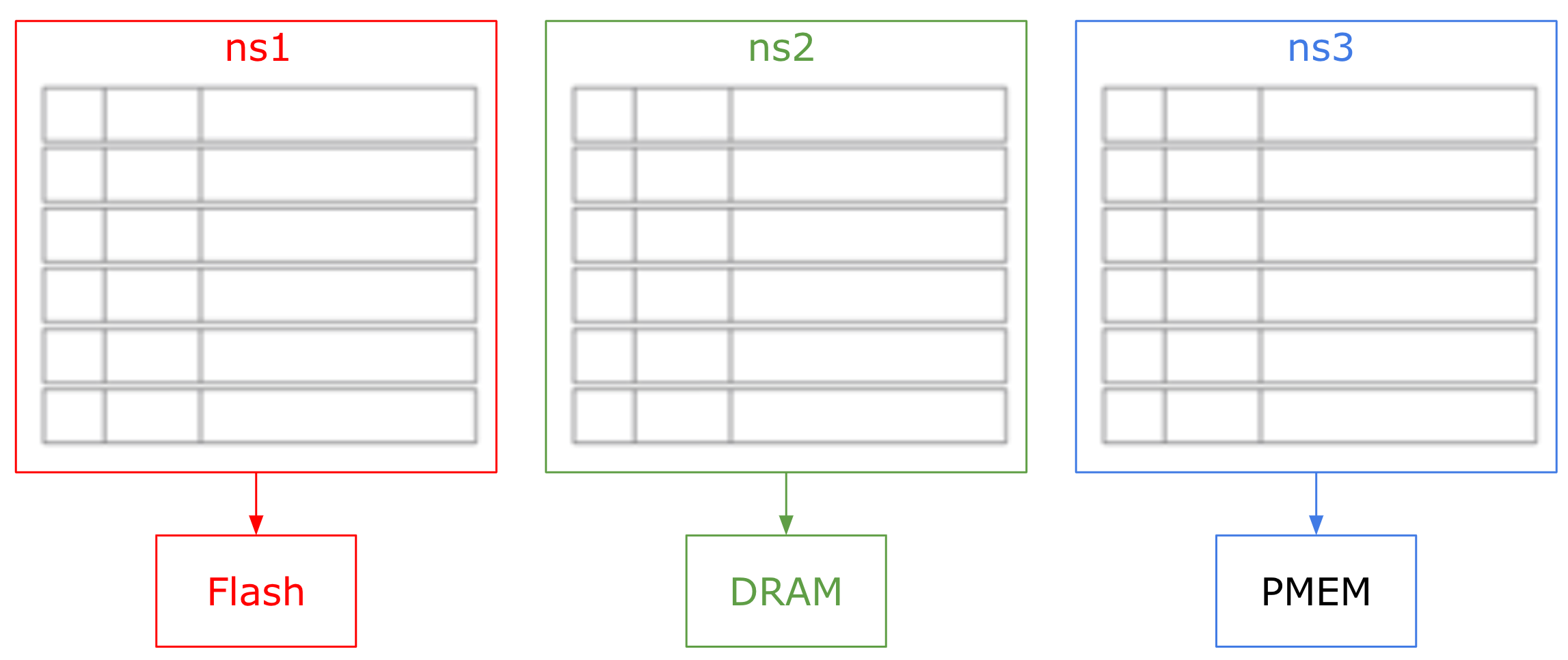
A database can exist with multiple namespaces, ns1, ns2, and ns3, each with its own storage engine.
- ns1 stores records on Flash/SSD.
- ns2 stores records in DRAM (in-memory).
- ns3 stores records in PMem.
Sets
In namespaces, records can belong to an optional logical container called a set. Sets allow applications to logically group records in collections. Sets inherit the policies defined by their namespace. You can define additional policies or operations specific to the set. For example, secondary indexes can be specified for a particular set, or a scan operation can be done on a specific set.
Records in the namespace do not have to be in a set, and instead just belong to the namespace.
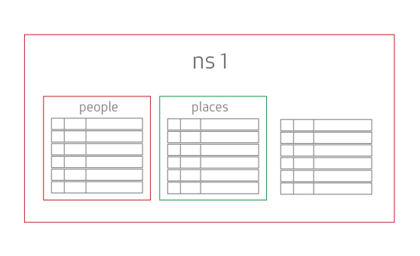
This shows two sets, people and places, that belong to the ns1 namespace, which also contains records not in a set.
Records
A record is the basic unit of storage in the database. Records can belong to a namespace or to a set within the namespace. A single record is uniquely identified by a key. Records are composed of:
| Component | Description |
|---|---|
| key | The unique identifier of the record. Records can also be accessed by the digest, a unique object identifier created by the client hashing the key. |
| metadata | Contains version information (generation count), the record's expiration (time-to-live or TTL), and last update time (LUT). |
| bins | Bins store the record data. The data type of the bin is set by the value of the data it contains. Multiple bins (and data types) can be stored in a single record. |
Keys and Digests
Using the client, the application performs operations on records stored in the database, by providing the key (or digest) of the record, and one or more operations (in an atomic transaction).
Metadata
Each record contains the following metadata:
- A generation count tracks a record modification cycle, its "lineage". The generation count is returned to the application on reads, which can use it to ensure that the data to be written has not been modified since the last read, using a check-and-set (CAS) pattern.
- Time-to-live (TTL) specifies an optional expiration time for the record. As of Aerospike database version 4.9, expirations are disabled by default. If a TTL is used, it will reset every time the record is written. For server version 3.10.1 and above, the client can set a policy to not modify the TTL when updating the record.
- last-update-time (LUT) specifies the timestamp of when the record was updated. This metadata is internal to the database and not directly returned to the client.
Bins and Data Types
The record data is stored in bins. Bins consist of a name and a value. Bins do not specify the data type, rather the data type is defined by the value contained in the bin. This dynamic data typing provides flexibility in the data model. For example, a record can contain the bin id with the string value bob. The value of the bin can always change to a different string value, but it can also change to values of a different data type, such as integer.
There is no schema, so each record can have its own varied set of bins. You can add and remove bins at will.
Bin values can be any one of the native supported data type.
For details about upper bounds for bins, see Upper Sizing Bounds and Naming.