Data Distribution
Aerospike Database uses a shared-nothing (SN) architecture, where:
- Every node in the Aerospike cluster is identical.
- All nodes are peers.
- There is no single point of failure.
Using the Aerospike Smart Partitions™ algorithm, data distributes evenly across all nodes in the cluster.
For convenience, we refer to the first copy of a partition as the master, and the second copy and each subsequent copy of a partition as replicas. In proper terms, all copies of a partition are replicas.
Partitions
In the Aerospike Database, a namespace is a collection of data that has common storage, such as on a specific drive, and policies, such as the number of replica copies for each record in the namespace. Each namespace is divided into 4096 logical partitions, which are evenly distributed between the cluster nodes. This means that if there are n nodes in the cluster, each node stores ~1/n of the data.
Record distribution to partitions
Aerospike uses a deterministic hash process to consistently map a record to a single partition.
To determine record assignment to a partition, the record's key (of any size) is hashed into a 20-byte fixed-length digest using RIPEMD160. The partition ID of the record is determined using 12 bits of this digest.
RIPEMD160, a field-tested, extremely random hash function, ensures that records distribute evenly on a partition by partition basis. Furthermore, Aerospike evenly distributes the record containing partitions across the nodes in a cluster, thus ensuring an even distribution of records to nodes.
Partition distribution to cluster nodes
Partition distribution in Aerospike has the following characteristics
- Aerospike uses a random hashing method to ensure that partitions distribute evenly to the cluster nodes. There is no need for manual sharding.
- All of the nodes in the cluster are peers – there is no single database master node that can fail and take the whole database down.
- When nodes are added or removed, a new cluster forms and its nodes coordinate to evenly divide partitions between themselves. The cluster automatically re-balances.
Because data distributes evenly (and randomly) across cluster nodes, there are no hot spots or bottlenecks where one node handles significantly more records than any other node. For example, in the United States, many last names begin with R. If data is stored alphabetically, the server handling the last names beginning with R has a lot more traffic than the server handling last names beginning with X, Y, or Z. Random data assignment ensures a balanced server load.
Data replication and synchronization
For reliability, Aerospike replicates partitions on one or more nodes. One node acts as the data master for reads and writes for a partition, while zero or more nodes act as read-only replicas for the partition, depending on the replication factor.
This illustrates a 4-node Aerospike cluster, where each node is the data master for roughly 1/4 of the data AND each node is the replica for 1/4 of the data. One node is the data master. Data distributes across all other nodes as replicas. For this example, if node 1 becomes unavailable, replicas from node #1 are spread across the other nodes.
The replication factor (RF) is configurable, however it cannot exceed the number of nodes in the cluster. More replicas provide better reliability, but create higher cluster demand as write requests must go to all replicas. Most deployments use a replication factor of 2 (RF2), one master copy and one replica.
With synchronous replication, write transactions propagate to all replicas before committing the data and returning results to the client. This ensures a higher level of correctness when there are no network faults.
In rare cases during cluster reconfiguration, the Aerospike Smart Client may send the request to the wrong node because it is briefly out of date. The Aerospike Smart Cluster™ transparently proxies the request to the right node.
When a cluster recovers from partitioning, writes to different partitions may conflict. In this case, Aerospike applies a heuristic to choose the most likely version to resolve conflicts between different copies of the data. By default, it chooses the version with the largest number of changes (highest generation count) is chosen. The version with the most recently modified time can be chosen, depending on the data model.
Aerospike cluster with no replication
In the Aerospike Database, having NO replicated data is replication factor of 1—there is only a single copy of the database.
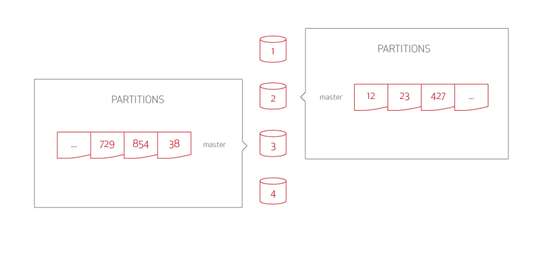
This illustrates two nodes of a four-node cluster that has a total 4096 partitions. Each node contains a random assignment of 1/4th of the data (1024 partitions). Each server/node manages this collection of partitions.
Each node is the data master for 1/4th of the data partitions. A node is the data master when it is the primary source for reads and writes to that data. The Aerospike Smart Client is location-aware. It knows where each partition is located so that the data retrieval is achieved in a single hop. Every read and write request is sent to the data master for processing. The Smart Client reads records and sends a request to the correct data master node for that record.
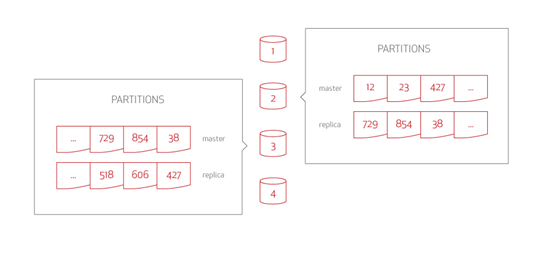
Aerospike cluster with replication
In the Aerospike Database, a replication factor of 2 (RF2) means storing two copies of the data: master and replica.
This illustrates that each node is the data master for 1/4 of the data (1024 partitions) AND that each node is the replica for 1/4 of the data (1024 partitions). Note that the data for one data master is distributed across all other cluster nodes as replicas. If node #1 becomes unavailable, the replicas of the data from node #1 distribute to all other cluster nodes.
The Smart Client reads records and sends a request to the correct data master node for that record. Write requests are also sent to the correct node. When a node receives a write request, it saves the data and forwards the entire record to the replica node. Once the replica node confirms a successful write and the node writes the data itself, a confirmation returns to the client.
Automatic rebalancing
The Aerospike data rebalancing mechanism distributes query volume evenly across all cluster nodes, and is persistent during node failure. The system is continuously available. Rebalancing does not impact cluster behavior. The transaction algorithms integrated with the data distribution system ensure that there is one consensus vote to coordinate a cluster change. Voting per cluster change, instead of per transaction, provides higher performance while maintaining shared-nothing simplicity.
Aerospike allows configuration options to specify how fast rebalance proceeds. Temporarily slowing transactions heals the cluster more quickly. If you need to maintain transactional speed and volume, the cluster rebalances more slowly.
During rebalance, Aerospike retains full RFs of all partitions until the replicas are in sync. Some in-transit partitions temporarily become a single replica, to provide maximum memory and storage availability as the cluster rebalances to new stability.
In Aerospike, capacity planning and system monitoring manage any failure virtually with no loss of service, and without operator intervention. You can configure and provision your hardware capacity, and set up the replication and synchronization policies so that the database recovers from failures without affecting users.
Succession list
When Aerospike hashes keys into a 20 byte digest using the RIPEMD160 algorithm, 12 bits of the digest form the partition ID. This ensures that the same key is always written to the same master and replica partitions.
Two primary algorithms determine which nodes own each partition.
The default algorithm,
uniform balance, distributes partitions across nodes as evenly as possible to balance cluster traffic.The original algorithm sought to minimize data movement during cluster changes.
In practice, most customers find uniform balance the optimal choice. Because it is algorithmically derived, the node on which a partition resides is equally deterministic.
In the non-uniform balance algorithm, rack awareness only affects the distribution of replica partitions across the cluster nodes.
With uniform-balance, the addition of rack awareness affects the master partitions as well.
Each partition has an ordered list of cluster nodes. This is the succession list, and it determines the succession of nodes that hold the replicas of a given partition.
The first node in the list holds the master partition.
The next node holds the first replica.
The third node in the list holds the second replica copy, and so on.
For the original algorithm optimizing data movements during cluster changes (node addition or removal), the order of the succession list for a given partition never changes. For example, if a node holding a partition is removed from the succession list, the partition migrates to the next node to the right in the list. But for the default prefer-uniform-balance=true algorithm, the order of nodes may change, causing more data movement but preserving the balance in terms of the number of partitions each node owns.
Consider the following rolling restart scenario. Data is persisted on disk. There are five nodes, A-E with an RF2, meaning there is one master and one replica. In this example, the succession list is A,B,C,D,E. The write load is constant and fill migrations are delayed. We also assume the order does not change when nodes leave or join the cluster; rack awareness and prefer-uniform-balance are not used.
Steady state succession list
Master Replica Other A B C D E Node A shuts down
When A shuts down, B becomes the master because it is next in the succession list and already holds a full copy of that partition. C becomes a replica-holding node. B initially does not have any records for that partition, but as write transactions are processed, it becomes the recipient of replica writes for that partition. When the configured migrate-fill-delay expires, C also receives fill migrations in order to eventually get a second full copy of that partition. Fill migrations are migrations targeting nodes that were not previously "full".
| Down | Master | Replica | Other |
|---|---|---|---|
| A | B | C | D E |
- A returns to the cluster
When A returns to the cluster, it comes back as a replica of the partition because nodes B and C may have taken writes in its absence. C is no longer considered a replica for the partition; its records for that partition are considered non-replica. However, the data from that partition on node C is not dropped until replication of each record is achieved. This happens when migrations for the partition complete and A reclaims the master ownership.
| Replica | Master | Non-Replica | Other |
|---|---|---|---|
| A | B | C | D E |
- As migrations are ongoing, B shuts down
When B shuts down before the migration of the partition completes, both A and C are subset partitions. A has not yet received full delta migrations and so could be missing some updates that came in while it was out of the cluster. C has the data A is missing; however, as fill migrations are delayed, it does not have the original data that resides on A. Here the succession list is very important because it defines which node is the master. Because A is first in the succession list, it becomes the master.
In other words, neither A or C has a full copy of that partition, but between them they have all the latest updates for all the records for that partition. If migration for the partition completed before taking node B down, node A would have been master and node C would have dropped the partition.
When a transaction for a record belonging to a partition has to be processed in this situation, where neither node A nor C has a full copy of the partition, the transaction leverages duplicate resolution. For namespaces which do not have strong consistency enabled, the following configuration parameters dictate the behavior:
| Master | Down | Replica | Other |
|---|---|---|---|
| A | B | C | D E |
- Node B returns to the cluster
When B returns to the cluster and steady state is restored, we are back to the initial state.
| Master | Replica | Other |
|---|---|---|
| A | B | C D E |
Implications of the succession list
- The succession list is based on the
node-idconfiguration parameter. If anode-idconfiguration changes, so does the succession list. - If a node leaves the cluster and returns with a new
node-id, even if it is the same physical machine, extra migrations may occur as the succession could have changed. - If
node-idis not explicitly set, it is derived from the fabric port configuration and the MAC address of the first network interface when the address is configured to "any". Also thenode-id-interfacewhich specifies the interface to use for the MAC address. If not specified, Aerospike chooses an interface based on some ordering heuristics. - When a node is quiesced, it moves to the end of the succession list for all partitions. This causes the node to give up master ownership for the partitions it owns and allows for smooth maintenance. Transactions move to the nodes that take ownership of master/replica partitions from the quiesced nodes.
- If the cluster size is equal to the replication factor then when quiesced, a node retains the (n-1)th replica where 'n' is the replication factor because the partitions have no other node they can reside upon.
Traffic saturation management
The Aerospike Database monitoring tools let you evaluate bottlenecks. Network bottlenecks decrease database throughput capacity, decreasing performance.
Capacity overflows
On storage overflow, the Aerospike stop-write limit prevents new record writes. Replica and migration writes, as well as reads, continue processing. So, even beyond optimal capacity, the database does not stop handling requests. It continues to do as much as possible to continue processing user requests.