Clustering
The Aerospike reliability guarantee starts with cluster failure detection. On failure of a cluster node or network event, Aerospike quickly recovers and reforms the cluster. To set up a cluster, you first install a single node, and then simply add additional nodes as you need them.
Active-active deployments
Multi-Site Clustering and Cross-Datacenter Replication provide two distinct mechanisms for deploying Aerospike in an active-active configuration. More information of the tradeoffs involved in using either model can be found in the article Active-Active Capabilities in Aerospike Database 5.
Heartbeat
Cluster nodes track each other using the heartbeat feature. Using a heartbeat, nodes can coordinate themselves. Nodes are peers. There is no master node. All nodes track the other nodes in the cluster. During node management, all cluster nodes detect changes using the heartbeat mechanism.
Aerospike defines a cluster using these methods:
- Multicast uses the IP:PORT to broadcast the heartbeat message.
- Mesh uses the address of one Aerospike server to join cluster.
This illustrates building a typical Aerospike cluster.
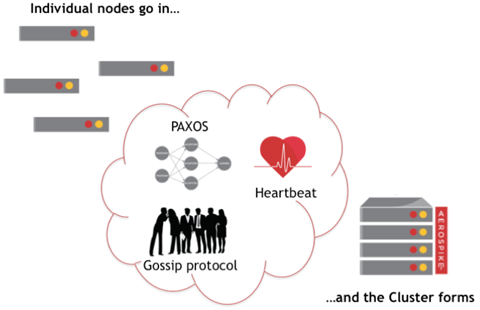
High-speed Distributed Cluster Formation
Once Aerospike detects cluster change, other nodes use a Paxos-based gossip voting process to determine which nodes form the cluster. The Aerospike Smart Partitions™ algorithm automatically re-allocates partitions and rebalances the cluster. The deterministic hashing algorithm always maps a record to the same partition. Data remains in the same partition for its entire life, but partitions can move from one server to another.
Aerospike uses a Paxos-based gossip algorithm to ensure agreement on a minimal amount of critical shared state. The most critical part of this shared state is the list of nodes participating in the cluster. Whenever a node arrives or departs, the algorithm runs to ensure agreement. This process takes a fraction of a second. After this phase, each node agrees on both the participants and their order in the cluster. Using this information, the master node for any transaction is computed as well as the replica nodes.
Since essential information about any transaction is computed, transactions can be simpler and use proven database algorithms. This results in minimal latency, since only a minimal subset of nodes is involved.
Clustering Benefits
The Aerospike distributed processing ensures data reliability. Other competing databases get high throughput from a single server with a large SSD. Aerospike provides both vertical scaling - several million transactions per second per server with Flash storage, 10's of millions with DRAM. With cluster, a database can provide both horizontal scale, and higher availability, since data is stored on multiple servers. If a server fails, all database access stops. A typical configuration has several nodes, and each node has several Flash devices.
Aerospike runs on fewer servers than other databases, which keeps costs low. Aerospike can assist in deployment planning to help you achieve optimal redundancy from as few servers as possible. In the Aerospike distributed, shared-nothing architecture, nodes are self-managing and coordinate to ensure reliability, which makes expansion easy as cluster traffic increases.
The integrated Aerospike smart client (included with any application using Aerospike APIs), your application can ignore node management and let the client handle cluster communication. The Aerospike Database provides monitoring tools to track capacity, bottlenecks, diagnose hardware failures, and so on.
In the Aerospike Database, even when storage reaches capacity or hardware fails, there is minimal impact on service.
What happens when a node fails?
In an example four-node cluster, if node #3 has a hardware failure, nodes #1, #2, and #4 automatically detect the failure. Node #3 is the master for 1/4th of the data, but those partitions also exist as replicas on nodes #1, #2, and #4. These nodes automatically perform data migration to copy the replica partitions and create data masters. For example, partition 23 is replicated on node #4 and copied to node #2, which becomes the new master for partition 23. At the same time, your application (which includes the Aerospike Smart Client™) becomes aware of the node #3 failure and automatically calculates the new partition map. This process occurs in reverse when a node is added to the cluster.
Using our example, when node #3 restarts and rejoins the cluster or when you add another node to the cluster to provide greater capacity, the nodes use the heartbeat to locate each other. When adding a node to the cluster, the cluster starts data migration to make the new node master for some partitions and replica for other partitions. The client automatically detects any changes, which ensures that future requests are sent to the correct node. Aerospike ensures cluster synchronization so that clusters act as hot replicas.
But what happens if an entire cluster goes down? See Cross-Datacenter Replication.