Streaming Writes and Reads with Aerospike and Structured Streaming
Writing streaming data to Aerospike
The Aerospike Connector for Spark can stream writes to an Aerospike database sink. For a streaming write, Spark needs a streaming source.
To illustrate with a working example, we will use an Amazon dataset in JSON format as the streaming source and an Aerospike database as the sink.
import org.apache.spark.sql.functions.{concat, lit}
import spark.sqlContext.implicits._
val readSchematics = StructType(
List(
StructField("reviewerID", StringType, nullable = true),
StructField("asin", StringType, nullable = true),
StructField("reviewerName", StringType, nullable = true),
StructField("helpful", ArrayType(IntegerType), nullable = true),
StructField("reviewText", StringType, nullable = true),
StructField("overall", FloatType, nullable = true),
StructField("summary", StringType, nullable = true),
StructField("unixReviewTime", LongType, nullable = true),
StructField("reviewTime", StringType, nullable = true),
StructField("reviewID", StringType, nullable = true)
)
)
val df=spark.readStream
.format("json")
.schema(readSchematics)
.load("json_file_directory")
val dropColumns= Seq("asin","reviewText","reviewerName", "summary","unixReviewTime")
//Let's clean our input stream. One could also perform some aggregations on stream.
val cleanedDF= df
.withColumn("__key", concat($"reviewerID", lit("-"), $"asin"))
.drop(dropColumns:_*)
//Write processed stream to Aerospike database.
val writer= cleanedDF.writeStream
.queryName("streaming_write_example")
.format("aerospike") //registered data source.
.option("checkpointLocation","hdfs://check_point/") //streaming requires checkpoint directory.
.option("aerospike.set", "streaming_set") //set used for writing streaming data.
.option("aerospike.seedhost", "localhost:3000")
.option("aerospike.namespace", "test")
.option("aerospike.updatebykey", "key")
.option("aerospike.featurekey", "feature_key_file_content")
.outputMode("update") // depends on performed stream operation.
.start()
Reading streaming data from Aerospike
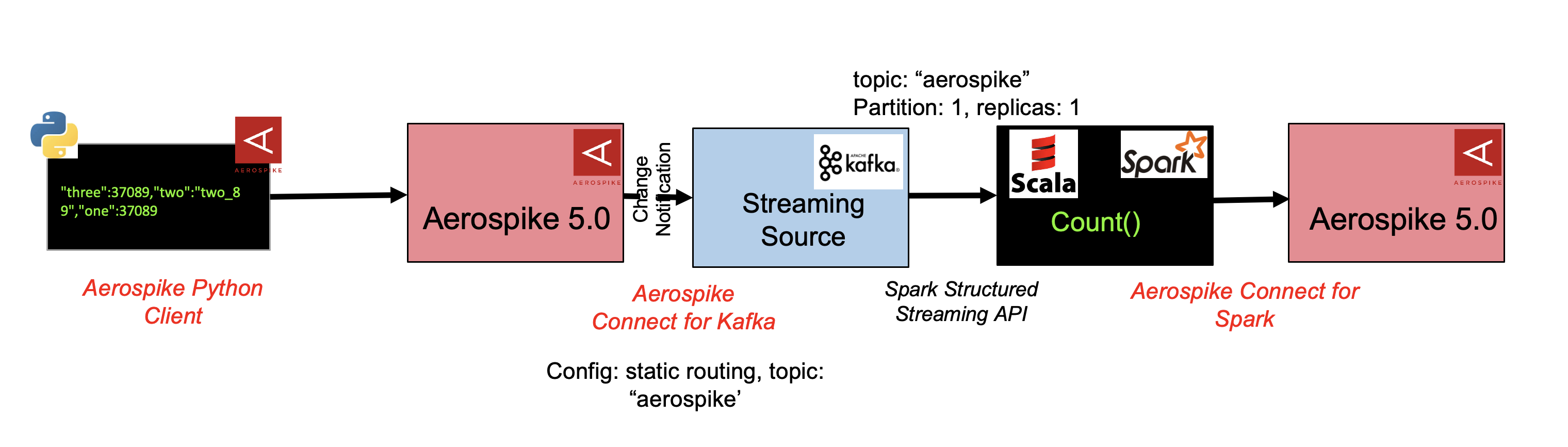
Aerospike Connect for Spark supports streaming reads using Structured Spark Streaming and Kafka as a streaming source. As shown in the diagram below, change notifications are streamed from the Aerospike database to Apache Kafka via the Kafka Connector. Data is then consumed from the Kafka topic and loaded into a streaming DataFrame by using Kafka as a streaming source.
Here is a sample Python app for writing into the Aerospike DB
import aerospike
import random
namespace= "device"
write_set= "streaming_write_set"
input_range = 1000000
config = {"hosts": [("127.0.0.1", 3000)]}
client = aerospike.client(config).connect()
for num in range(1, input_range):
key = (namespace, write_set, num)
client.put(key, {"one": num, "two": "two_" + str(num), "three" : num })
Configure the Change Notifications
Configure Aerospike for Change notifications
Configure the Connector
Configure Aerospike Kafka Source Connector.
Create a topic in Kafka called aerospike and tune Kafka for low latency.
Please refer to the Kafka documentation of the distribution that you are using.
Following messages are written to Kafka aerospike topic via the Aerospike Kafka outbound connector.
{ "metadata":{
"namespace":"device",
"set":"streaming_write_set",
"digest":"jlIN9k6icUOYE7oa1FzmK/NY5EU=",
"msg":"write",
"gen":27,
"lut":0,
"exp":0
},
"three":26426,
"two":"two_26426",
"one":26426
}
You can use Kafkacat on the broker to view the above messages that are streamed through Kafka.
Consume the messages from Kafka using the Spark Streaming APIs
Here one, two, three are bin names.
The schema of the message is:
val readSchematics = StructType(
List(
StructField ("metadata", MapType(StringType, StringType, true),true ),
StructField ("one", LongType,true ),
StructField ("two", StringType,true ),
StructField ("three", LongType,true )
)
)
Consume the message:
val df = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "KAFKA_BROKER_IP:PORT")
.option("subscribe", "aerospike")
.load()
.select(from_json(col("value").cast("string"), readSchematics).alias("tmp")).select("tmp.*")
.groupBy("one").count() //do some processing here.
Persist the streaming result into Aerospike
You could consider persisting the data into Aerospike using the following API:
df.writeStream
.queryName("kafa_source_aerospike_destination")
.option("checkpointLocation","/tmp/check_point/")
.format("aerospike")
.option("aerospike.writeset", "destination_set") //Be mindful of not reading and writing into same source and destination
.option("aerospike.seedhost", "localhost:32812")
.option("aerospike.namespace", "memory")
.option("aerospike.updatebyKey", "one")
.option("aerospike.featurekey", "PATH_TO_FEATURE_KEY")
.outputMode("update")
.start()
.awaitTermination(500000)