Secondary Index
Prior to Server 6.0, primary index (PI) queries were called scans and secondary index (SI) queries were called queries.
What is a secondary index?
A secondary index (SI) is a data structure that locates all the records in a namespace, or a set within it, based on a bin value in the record. When a value is updated in the indexed record, the secondary index automatically updates. From Aerospike Database server 6.0, SI query results are unaffected by the state of the cluster. Querying by partition returns correct results when the cluster is stable, and during data migration after a cluster size change. In server 6.0, compatible clients, such as Java client 6.0, are needed to support rebalance-tolerant queries.
Applications that benefit from secondary indexes include rich, interactive business applications and user-facing analytic applications. Secondary indexes also enable Business Intelligence tools and ad-hoc queries on operational datasets.
Why use a secondary index?
Scanning large amounts of data can take large amounts of time, and can negatively affect performance when SI queries scan every document or entry in a table.
Querying large amounts of data by reading every document or entry in a table is expensive in time and performance. Aerospike secondary indexes guarantee faster response times because they provide efficient access to a wider range of data through fields other than the primary key.
Aerospike secondary indexes:
- Are stored by default in memory for fast lookup. It's also possible
to store secondary indexes other ways by setting the
sindex-typeconfiguration parameter. See Secondary index storage for more information. - Are built on every node in the cluster and are co-located with the primary index. Each secondary index entry contains only references to records local to the node.
- Contain pointers to both master records and replicated records in the node.
- Are on a bin value, which allows to model one-to-many relationships. For List and Map (document) type bins, a
contextcan be added to identify a value of that type to index. - Are specified bin-by-bin (such as, with Rational Database Management System (RDBMS) columns) for efficient updates and a minimal amount of resources required to store indexes. Use Aerospike tools or the API to dynamically create and remove indexes based on bins and data types. Index entries are type checked. For instance, a bin can store a user age as a string by one application, and as an integer by another. An integer index excludes records stored as a string, while a string index excludes records stored as integers.
Secondary index metadata
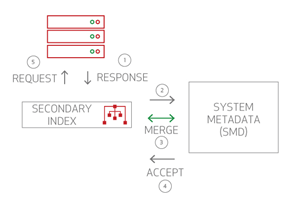
Aerospike tracks which indexes are created in a globally-maintained data structure: the System Metadata (SMD) system. The SMD module resides in the middle of multiple secondary index modules on multiple nodes. Changes made to the secondary index are always triggered from the SMD.
SMD workflow:
- An info request send from a client to any node forwards an SMD action, and then to the SMD principal node.
- From the SMD principal node, it forwards the action to every node, where the SMD module notifies the sindex module.
- All nodes apply the action, that is, it triggers the building of a new sindex.
Secondary index creation
You can dynamically create, read, and delete secondary indexes with the Aerospike asadm tool. To build a secondary index, specify a namespace, set, bin, container type (none, list, map-keys, and map-values), and data type (integer, string, Geospatial). On confirmation by the SMD, each node creates the secondary index in write-only (WO) mode, and starts a background scan to scan all data and insert entries in the secondary index.
- Secondary index entries are only created for records matching all of index specifications.
- The scan populates the secondary index and interacts with read/write transactions exactly as a normal scan, except that there is no network component to the index creation. During index creation, all new writes affecting the indexed bins updates the corresponding secondary indexes.
- Each node independently marks every secondary index as readable. When building the secondary index finishes on a node, it is marked as read active on that node.
- If a node with data joins the cluster, but is missing index definitions in its SMD file, indexes are created and populated based on the latest SMD information. During index population, queries are not allowed to ensure that data on the incoming node is clean before it is available.
- Optionally, you can provide a
contextwithin the bin to index the fields of a Map (document) or List data type.
Priority of secondary index creation
The index creation scan only reads records already committed by transactions (that is, no dirty reads are allowed). This means that scans can execute at full speed, provided there are no record updates to block reads.
To ensure that the index creation scan does not adversely affect the latencies of ongoing read and write transactions, the default settings suffice because they balance long running tasks (such as data rebalancing and backup) against low-latency read/write transactions. If necessary, you can control resource utilization for the index creation scan.
For server 5.7 and later, modify
sindex-builder-threads configuration at the service level.
Prior to server 5.6, use the job prioritization settings.
- For Server 5.7 and later, modify
sindex-builder-threadsconfig at the service level. - For Server prior to 5.6, use the job prioritization settings.
Writing data with secondary indexes
On data writes, the current indexes are checked. For all bins with indexes, a secondary index update-insert-delete operation is performed. Aerospike is a flex schema system: If no index value exists on a particular bin or if the bin value does not support an index type, then the corresponding secondary action is not performed. All changes to the secondary index are performed atomically with the record changes under single-lock synchronization. Updating a secondary index has minimal impact on write latency.
Garbage collection
For non-durable deletes triggered by a client delete, expiry, eviction, truncation, or migration operations that drop partitions, records are not read from disk when deleting the entry from the secondary index. This avoids unnecessary burden on the I/O subsystem. The remaining entries in the secondary index are deleted by a background thread, which wakes up at regular intervals and performs cleanup. For namespaces with data in memory or primary index in flash, garbage collection is currently only used for dropped partitions.
Distributed SI queries
Every cluster node receives the query to retrieve results from the secondary index. When the query executes:
- Requests “scatter” to all nodes.
- Records are read in parallel from secondary indexes and data storage.
- Results are aggregated on each node.
- Client “gathers” results from all nodes and returns them to the application.
An SI query can evaluate a long list of primary key records. This is why Aerospike performs SI queries in small batches.
Batching also occurs on client responses, so if a space threshold is reached, the response is immediately flushed to the network, much like return values in an Aerospike batch request. This keeps space usage of an individual SI query to a constant size, regardless of selectivity.
SI queries progress on a moving target. Data on the cluster might be undergoing modification by clients while the query is progressing. Although the SI query process ensures that results sync with actual data every time an SI query executes and the record is scanned, if records are undergoing change, the following scenarios may happen and should be taken into consideration when designing the data model.
- In Strong Consistency mode, SI query may return records that have not yet completed replication.
- When doing an integer range query, if value in the indexed bin happens to increase within the range, SI query may return the record twice.
- When doing an integer range query, if value in the indexed bin happens to decrease within the range, SI query may miss returning the record.
SI query execution during migrations
Getting accurate SI query results is complicated during data migrations. When a cluster node is added or removed, it invokes the Data Migration Module to transition data to and from nodes as appropriate for the new configuration. During the migration operation, a partition may be available in different versions on many nodes.
When a node is added or removed from an Aerospike server version 6.0 cluster, the smart client works with the server to ensure that records aren’t repeated or missed due to a partition migration. The client tracks the cluster state, and will reschedule accessing partitions that are migrating, returning to query them when they’ve fully migrated.
Aggregation
SI query records can feed into the aggregation framework to perform filtering, aggregation, and so on. Each node sends the SI query result to the User-Defined Function (UDF) sub-system to start results processing as a stream of records. Stream UDFs are invoked and the sequence of operations defined by the user are applied to the SI query results. Results from each node are collected by the client application, which can then perform additional operations on the data.
Performance techniques
To ensure aggregation does not affect overall database performance, Aerospike uses these techniques:
Global queues manage records fed through the different processing stages, and thread pools effectively utilize CPU parallelism.
The SI query state is shared across the entire thread pool so that the system can manage the Stream UDF pipeline.
Except for the initial data fetch portion, every stage in aggregation is a CPU-bound operation. It is important that processes finish quickly and optimally. To facilitate this, Aerospike batches records and caches UDF states to minimize system overhead.
For namespace operations where data is stored in-memory and no storage fetch is required, Aerospike implements stream processing in a single thread context. Even with this optimization, the system can parallelize operations across data partitions because Aerospike natively divides data as a fixed number of partitions.
Secondary index storage
The storage of a secondary index is determined by the sindex-type
configuration parameter. The following options are available:
| Type | Description |
|---|---|
shmem | Linux shared memory. |
flash | A block storage device (typically NVMe SSD). |
pmem | Persistent memory (e.g. Intel Optane DC Persistent Memory). |
As of server 6.1 of Aerospike Database Enterprise Edition (EE) and Aerospike Database Standard Edition (SE), secondary indexes are stored by default in shared memory (shmem). Since then, all secondary index storage types take advantage of Aerospike's fast restart capability.
The sindex-type configuration is not avalable for Aerospike Community Edition (CE). CE stores primary and secondary indexes in volatile process memory.
For more information about secondary index storage methods, see Configure the Secondary Index.